[IJCAI 2022] AggPose: Deep Aggregation Vision Transformer for Infant Pose Estimation
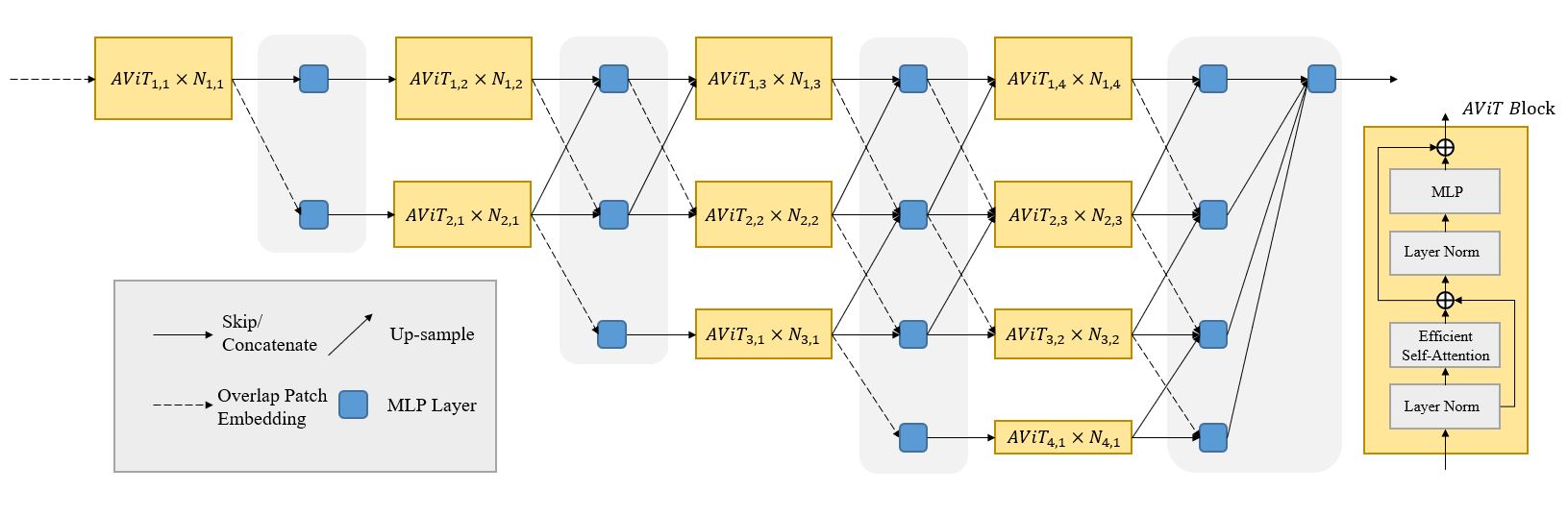
Movement and pose assessment of newborns lets trained pediatricians predict neurodevelopmental disorders, allowing early intervention for related diseases. However, most of newest approaches for human pose estimation method focus on adults, lacking publicly large-scale dataset and powerful deep learning framework for infant pose estimation. In this paper, we fill this gap by proposing Deep Aggregation Vision Transformer for human (infant) posture estimation (AggPose), which introduces a high-resolution transformer framework without using convolution operations to extract features in the early stages. It generalizes Transformer + MLP to multi-scale deep layer aggregation within feature maps, thus enabling information fusion between different levels of vision tokens. We pre-train AggPose on COCO pose estimation and apply it on our newly released large-scale infant pose estimation dataset. The results show that AggPose could effectively learn the multi-scale features among different resolutions and significantly improve the performance.